
Most AI agents today are brilliant but forgetful. Once the session ends, their "brain" resets to zero. They can write elegant code, reason through complex problems, and engage in nuanced conversations, but they cannot remember what happened yesterday. To truly become agentic, an AI needs something more: persistent memory that survives across conversations, tasks, and system restarts.
In this article, we'll explore how to design persistent memory for AI agents, the patterns used to implement it, and which datastores make it scalable and reliable.
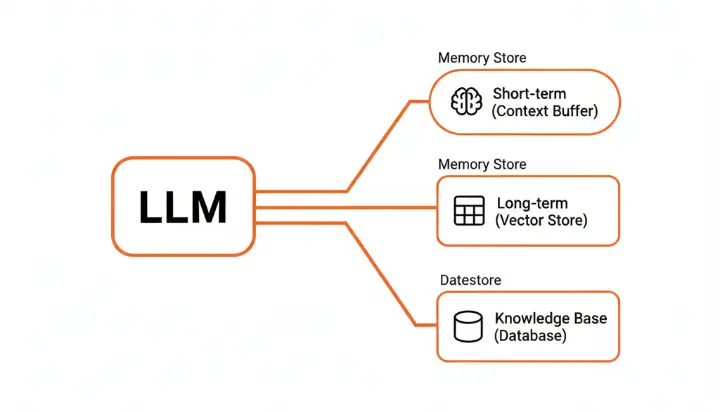
Understanding Persistent Memory in Agentic AI
When we talk about memory in AI agents, we're actually dealing with two distinct types:
Ephemeral memory exists only during a session. This includes the context window and chat history that disappears when the conversation ends. Think of it as RAM: fast, accessible, but volatile.
Persistent memory is stored and retrievable across sessions or system restarts. This is your hard drive: it keeps user context, preferences, past goals, and learned experiences available for future interactions.
The difference is transformative. An agent with persistent memory can remember that you prefer Italian restaurants, recall the project specifications you discussed last week, and build on previous reasoning without starting from scratch.
Core Design Patterns for Agent Memory
Building effective persistent memory requires thoughtful architectural patterns. Here are the most proven approaches:
Embedding-Based Retrieval Pattern
This pattern converts memories into vector embeddings and stores them in specialized vector databases like ChromaDB, Milvus, or Pinecone. When the agent needs to recall information, it performs a semantic search to retrieve the most relevant memories.
The beauty of this approach lies in its flexibility. Unlike keyword search, vector-based retrieval understands meaning and context. When a user asks "Where should I eat tonight?" the agent can retrieve the memory "I love Italian food" even though the words don't match exactly.
Popular frameworks like LangChain, LlamaIndex, and CrewAI all leverage this pattern as their foundation for agent memory.
Hybrid Memory Pattern
The hybrid approach combines symbolic structured databases with semantic vector stores. Structured data like facts, preferences, and transaction logs go into SQL databases, while longer text passages and experiential knowledge live in vector stores.
This gives agents the ability to recall both exact data and fuzzy experiences. Need to know a user's account ID? Query the SQL database. Want to understand their communication style? Search the vector embeddings of past conversations.
Timeline or Event Stream Pattern
Some applications require a complete audit trail of agent interactions. The timeline pattern stores each interaction as a timestamped event, creating a chronological record that can be replayed or analyzed.
This approach works exceptionally well with systems like Kafka, Postgres, or TimescaleDB. It's particularly valuable for compliance-heavy industries, debugging agent behavior, and training future models on real interaction patterns.
Reflection Loop Pattern
Inspired by how human memory consolidates during sleep, the reflection loop pattern has agents periodically review their own logs. The agent summarizes or compresses older memories, extracting key insights while discarding irrelevant details.
This pattern serves two purposes: it reduces storage costs and improves retrieval relevance by focusing on distilled knowledge rather than raw interaction logs.
Choosing the Right Datastore
Different memory requirements call for different storage solutions:
Vector databases like ChromaDB, Milvus, and Pinecone excel at semantic recall. They offer fast similarity search and straightforward APIs, though they require generating embeddings for all stored content.
Relational databases such as Postgres and SQLite work best for structured memory: user preferences, configuration settings, and factual data. They provide reliability and ACID compliance but lack semantic search capabilities.
Key-value stores like Redis and DynamoDB shine for short-term caching and low-latency access. They're perfect for temporary session data but offer limited support for complex querying.
Hybrid solutions like Weaviate and LanceDB combine structured schemas with semantic search, giving you the best of both worlds at the cost of increased setup complexity.
Implementation in Practice
Here's a simple example using LangChain and ChromaDB:
from langchain.memory import VectorStoreRetrieverMemory
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
embedding_model = OpenAIEmbeddings()
vectorstore = Chroma(
persist_directory="./memory",
embedding_function=embedding_model
)
memory = VectorStoreRetrieverMemory(
retriever=vectorstore.as_retriever()
)
memory.save_context(
{"input": "I love Italian food"},
{"output": "Got it!"}
)
relevant_memory = memory.load_memory_variables(
{"input": "Where should I eat tonight?"}
)
This basic pattern can be extended with summarization layers, time-based memory expiration, and multiple specialized vector stores per agent.
Real-World Architectures
Modern agentic systems combine these patterns in sophisticated ways:
CrewAI and AutoGPT use vector stores paired with summary memory, periodically condensing older interactions into high-level insights.
ReAct and RAG systems implement reflection-based consolidation, where agents reason about what information is worth retaining.
Personal AI systems like Vutler deploy hybrid architectures, using Postgres for structured user data alongside Milvus for semantic memory of conversations and experiences.
Challenges and Future Directions
As persistent memory systems mature, several challenges remain:
Memory bloat requires intelligent forgetting strategies. Not everything deserves permanent storage, and agents need mechanisms to determine what to retain and what to discard.
Data privacy demands careful attention to user consent and secure deletion. Memory systems must support true data removal, not just logical deletion.
Compression techniques using embeddings or LLM summarization can reduce storage requirements while preserving essential information.
Multi-agent shared memory opens exciting possibilities for collaborative AI systems that learn from each other's experiences.

Conclusion
Persistent memory transforms AI agents from stateless responders into context-aware reasoning machines. It bridges the gap between simple interaction and genuine intelligence, letting agents learn, adapt, and grow over time.
As agents evolve from task executors to autonomous collaborators, memory becomes the foundation of their agency. The patterns and datastores we choose today will determine how effectively our AI systems can serve us tomorrow.